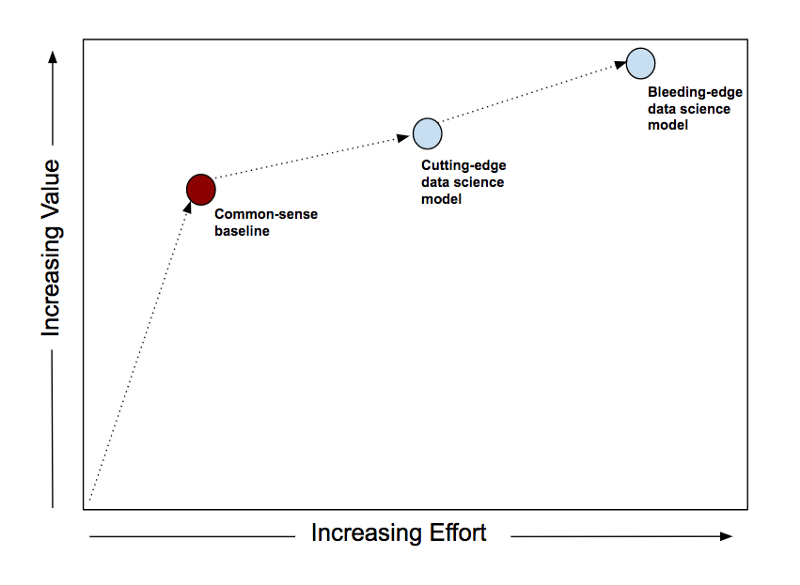
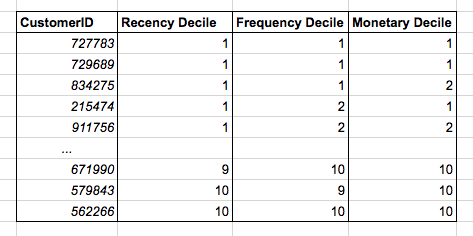
Editor's note: Dr. MIT, former Salesforce SVP, and data scientist Rama Ramakrishnan reminded that when engaging in data science projects, develop the good habit of creating a baseline first, deliver value quickly, and avoid self-deception. When you are ready to solve a data science problem, you may want to go straight ahead and start creating models directly. Don't do this. First create a common sense baseline. The common sense baseline refers to how you would solve this problem assuming you don’t understand data science. Suppose you know nothing about supervised learning, unsupervised learning, clustering, deep learning, etc. Now ask yourself, how do you solve the problem at hand? For experienced practitioners, it is routine to first create a common sense baseline. They will first think about the data and the problem, develop some intuition about what makes the solution better, and consider some things to avoid. They will discuss with commercial end users who may have solved this problem manually before. Experienced practitioners will tell you that common sense baselines are not only easy to implement, but often difficult to beat. Even if the data science model does defeat these baselines, the advantage may be small. Direct mail Let's look at three examples, starting with a direct sales example. You work for a clothing retailer and you have a customer database that includes information about every customer who bought something from you last year. You want to send emails to some customers to promote the latest spring clothes, and the budget can support sending emails to 100,000 customers in the database. Which 100,000 should you choose? You are probably already planning to create a training set and a test set, and train some supervised learning models. Maybe it's random forest or gradient boosting. Even deep learning. These are very powerful models, and your toolbox should always have them. But, first ask yourself a question: "If none of these methods exist, and I have to rely on my own cleverness to solve this problem, how do I pick out these 100,000 customers?" Common sense tells you that you should choose the most loyal customers. After all, they are the people most likely to be interested in emails. (However, in fact, this issue can also be considered from the perspective of Uplift Modeling. Whether you send an email or not, the most loyal customers tend to buy things from you, but to the less loyal Customers send emails, the increment is higher.) So, how would you measure loyalty? Intuitively speaking, loyal customers tend to buy more and spend more money. So you can calculate how much money each customer spent with you last year and how many times have they bought something from you? After doing this calculation, look at the result and you will find that it describes loyalty very well. But you also noticed that this will select customers who were loyal in the first half of the year and "missed" in the second half of the year. This problem can be corrected by checking the customer’s recent purchases at your place. If the cost is similar to the frequency of purchase, then the customer who bought something from you yesterday is worth more than the customer who bought it 11 months ago. To summarize, you calculate for each customer: Spending at you in the past 12 months The number of transactions that have occurred with you in the past 12 months How many weeks have passed since the last transaction You can sort the customer list based on the three measures above: The measurement is converted to a 10-point system (tenths) Select the first 100,000 customers among them. Congratulations! What you have just discovered is the highly valuable RFM (Recency-Frequency-Monetary) heuristic algorithm, the most tried-and-tested algorithm in the direct selling field. In case you are curious about which of R, F, M is the most important, according to research, R is the most important. The RFM method is easy to create, easy to explain, and easy to use. The best part is that it is surprisingly effective. Experienced direct selling practitioners will tell you that even when a more complex model defeats RFM, the gap between the two is much smaller than you think, making you doubt whether it is necessary to build a complex model. Recommended system Next, let's look at an example of a recommendation system. The clothing retailer you work for has an e-commerce website that requires you to create a product recommendation area, which will be displayed on the homepage. Clothing recommendations need to be personalized-if visitors have visited your site before, you need to recommend products that meet their tastes based on historical data. Some books discuss this topic throughout, and there are many libraries specifically developed for this on GitHub. Should you start applying matrix factorization directly ( At some point you should probably try matrix factorization, but you should not directly apply matrix factorization at first. You should first create a common sense baseline. What is the easiest way to display relevant products to visitors? best sale goods! Yes, they are not personalized. But the best sellers are best sellers because there are enough visitors to buy them. So in this sense, it is very likely that at least a considerable part of visitors will be interested in these products, even if these products are not customized according to the visitors' interests. In addition, anyway, you need to be prepared to show best-selling products, after all you need to show something to first-time visitors who have no data. Selecting best-selling products is easy. Determine a time window (the last 24 hours, the last 7 days, ...), determine a measure (profit, visits, ...), determine the calculation cycle (hourly, daily, ...), write a query request and add it automation. And you can adjust this baseline and add a little bit of personalization. For example, if you remember the product category that the visitor browsed last time on the site, then you can directly select the best-selling products from this specific category (rather than selecting the best-selling products of all categories) and display them in the recommended area. For example, a visitor who browsed the women's clothing category during their last visit can show her best-selling women's clothing. It needs to be clarified that the "adjustment" described above involves development work, because you need to "remember" information about different access sessions. However, if you plan to create and deliver model-based personalized recommendations, then the development of these collections of information is inevitable. Pricing optimization The last example is retail pricing optimization. As a clothing retailer, you sell seasonal items—for example, sweaters—at the end of the season, you need to clear your inventory to make room for the next season's items. The standard practice in the apparel industry is to reduce prices. If the discount is too small, you will have to clear the backlog of seasonal products at the price of scrap recycling at the last moment. If the discount is too large, seasonal products will soon be sold out, but you lose the opportunity to make more money. In the apparel industry, the art of balancing the two is called clearance optimization or price reduction optimization. There is a large amount of literature on how to use data science techniques to model and solve this problem (for example, Chapter 25 of the Oxford Price Management Manual, Declaration of Interest: I wrote this book). But let us first consider how to create a common sense baseline. Imagine that you have 100 units of sweaters on hand and there are 4 weeks left in this season. The price can be adjusted once a week, which means that you have 4 chances to make adjustments. Should you start reducing prices this week? Well, consider first, how many units of sweaters can you sell in the next 4 weeks if you keep the price unchanged? How do we estimate this value? The easiest way to do this is to see how many sold in the last week. Assume that 15 units were sold last week. If the situation in the next 4 weeks is similar to the previous week, then we will sell 60 units, and there will be a backlog of 40 units at the end of the season. Not good. Obviously a price reduction is needed. Retailers sometimes use discount ladders, 20% off, 30% off, 40% off... The easiest way is to first step up to the first step of the discount ladder, that is, the 20% discount will start next week. Fast forward one week. Let's say 20 units are sold, and 80 units and 3 weeks are left. Assuming that the same selling rate is maintained for the remaining 3 weeks (for example, 20 units per week), a total of 60 units will be sold, and there will still be a backlog of 20 units at the end of the season. So you need to go one step down the discount ladder, and start to increase the promotional efforts next week and change to 30% off sale. By analogy, repeat the above strategy every week until the end of the season. Depending on how responsive the selling rate is to discounts, different commodities may follow different discount paths. For example, compared to product A in the figure below, product B needs a stronger discount stimulus. This common sense baseline can be achieved through very simple if-then logic. Like the personalized recommendation example above, we can also adjust it (for example, we used the number of sales units from the previous week to "predict" the sales volume in the next few weeks, but we can also use the average sales of the previous weeks the amount). Once you have the baseline, you can move forward and unleash all the firepower of data science. But no matter what you do, you need to compare the results with the baseline to accurately assess the return on your work. Concluding remarks On many issues, the old 28th rule still applies. Common sense baselines can often allow you to get 80% of the value very quickly. As more and more data science technologies are applied, you will see higher value, but the rate of value growth is getting slower and slower. Depending on the circumstances, you can of course decide to use a complex scheme to extract the last bit of value. But you should only do this if you are very aware of the increased costs and benefits. A common sense baseline can fundamentally protect you from the famous danger mentioned by Richard Feynman: The first principle is that you must not fool yourself, and the person most easily fooled is yourself. Creating a data science model can be a very enjoyable process. It’s easy to fool yourself. The complex, painstaking, and well-tuned model you create (from a cost/benefit perspective) is better, but in fact it’s not Not so good. Common sense baselines can deliver value quickly and avoid self-deception. Please develop the good habit of creating a baseline first. 230V Single Color Led Strip,Single Colour Led Strip Lights,Led Single Colour Dimmer,Led Strip Single Color NINGBO SENTU ART AND CRAFT CO.,LTD. , https://www.lightworld-sentu.com

 click to read)?
click to read)?