Ron WIlson The deep learning network has so far achieved many victories in the human contest. They have surpassed humans in the classification of still images, at least slightly better. They have already defeated the world champion in chess. They have become the tool of choice for solving big data analysis problems from customer service to medical diagnosis. They have proved that after training, they can be small enough to stuff a smartphone. So, have we reached the end of the artificial intelligence (AI) history? Or is this just a small spray in the wider ocean? The current dazzling variety of excess artificial intelligence methods may give us an answer. It is true that there is always an alternative to a successful technology, because each doctoral student must find unique content to write, and must evade every patent. However, many of the current alternatives for deep learning networks have gradually got rid of the practical problems faced by traditional static networks such as AlexNet. Many programs are solving practical problems and investing in production systems. If you want to design a system that uses machine intelligence, think twice. Before we study a specific learning system, let us briefly understand the theory. For engineers, deep learning networks may be like digital simulations of our own neurons. But for mathematicians, this network is no different from the classic optimization problem that has a history of centuries, but it is different from the graphical representation. Imagine a 100% accurate image classification network. It's actually very simple. Simply build a large lookup table that assigns a position to each possible combination of pixel values ​​in the input image. To train the network, all you need to do is add tags that describe specific images in each location. For very limited tasks such as low-resolution optical character recognition, the system uses this approach. But for high-definition camera images, this table will be extremely large and a waste of resources. So this is still a mathematician's question. The deep learning network is used to reduce the size of the data table and reduce the number of connections by adding more hidden layers. How many tiers are added and how each tier's location is connected to the top tier is a matter of art and perspective. No one knows how to optimize. So everyone starts with the topology that they or their team knows or is using. However, the weights assigned to each node for each connection can be mathematically optimized locally, returning the desired answer through the network, and applying a gradient descent algorithm to find the weight that can most effectively reduce network output errors. This is just a process in a large family of optimization techniques that is most effective in reducing estimation errors. In addition, there are familiar technologies such as linear regression, as well as esoteric technologies such as multiple naive Bayesian learning methods. Many technologies have different algorithms, requirements, and capabilities. However, these methods essentially map a large number of possible input data to a simpler series of output data, minimizing the number of connections in the computational image and minimizing errors in the results. Which algorithm you choose may depend on your training and the surrounding environment, because it depends on the suitability of the algorithm for solving specific problems. In this huge space, most of the recent important events have focused on the small family of "deep learning networks." Most of them focus on one task (static data classification) and one subset of deep learning (convolutional neural network) (CNN, Figure 1). However, CNN's restrictions have led to relocation from people's existing practices to new implementations of CNN, other types of networks, and other types of analytical tools. This migration will expand the scope of the technology, system architects should pay attention to this, and it will also increase the risk of binding the design to the wrong hardware. For example, such migrations are needed to explore the mathematical operations inside traditional CNNs. When the network is implemented in software, the weight of the connection is usually displayed as a floating-point number. This practice requires installation and implementation on hardware accelerators such as graphics processing units (GPUs) and ASICs. However, a large amount of conventional processing is performed in the hidden layer of the deep network. Some may wonder if they really need to use 32-bit floats for weights that are just accumulating and benchmarking to 1. In fact, recent work has shown that the use of three-valued (-1, 0, and +1) or binary-weighted networks can basically perform the same topology as floating-point weighting. This discovery can omit many multiplications and additions (if the hardware is flexible enough to take full advantage of this advantage). Another example involves the topology of the network. Before training, the topological structure of the deep learning network (how one layer of nodes is connected to the nodes of the next layer) begins with the assumptions made by the researchers based on experience. For researchers, the risk of insufficient number of connections is much greater than the inconvenience caused by the excessive number of connections. When you train the network, the connection remains fixed, but some weights are zeroed. Other weights are interpreted as being irrelevant by other weights connected or downstream. Therefore, training does not eliminate connections, but some of these connections do not affect network output. As training progresses, more and more connections become irrelevant until the actual network becomes very sparse. According to studies, calculation inference through these sparse networks can use the same technique in sparse matrix calculations. This may be very different from the method you use when simply assuming that each weight must be optimized at training and applied at the time of inference. We have already discussed the calculation algorithm adjustment of the deep learning network. But there are some issues that need to use different types of networks in combination. Static networks need to first assume that the input data remains stationary during the analysis. They assume that the next input data has nothing to do with the current current input data. This is very useful when tagging photo stacks. But what if the task needs to extract meaning from the speech recording? What if we were dealing with the video stream used to determine car navigation? In these cases, the interpretation of a frame of data depends to a large extent on the previous content. Unsurprisingly, the researchers reported that the best results were obtained through neural networks with memory. The simplest form of neural network with memory is called Recurrent Neural Network (RNN, Figure 2). Basically, this is a simple network (as simple as a hidden layer) that can feed back some of the output data to the input data. The RNN judges the inference condition regarding the input data of the current frame from the inference of the previous frame (or its hidden layer result). Since we expect the real world to gain an advantage through a certain degree of persistence and causality, this is a very reasonable way to explain the flow of data in the real world. But sometimes you want longer memories. For video, all the information that can be used to improve the current frame inference results may be included in the previous frame or the first two frames. However, in a conversation or written text, the meaning of a word may be limited to a phrase before a few words, or to a book introduction in a page with Roman numerals. In view of this situation, the researchers developed a long-term short-term memory (LSTM) network. The LSTM network is a subset of the RNN. It has a more complex internal structure that allows selected data and inference loops to take longer. Natural language processing seems to be a promising application, and adding a slow-growing background environment for autopilot sensor fusion may also be. The interesting thing about RNNs is that since they are a form of traditional neural networks, it is in principle possible to train by expecting the back-propagation of the output data and the optimal weight gradient descent calculations. But there are some problems. In order to feedback loop counts, some researchers have developed the RNN as a series of interconnected traditional networks, much like the loops in software optimization. This supports the parallelization of tasks that still require a lot of computation. Since you are training the network to respond to sequences rather than static events, the training data must be a sequence. Therefore, training the RNN is not easy. Training can be very time consuming. Network weights may not be merged. Trained networks may not be stable. Some researchers use optimization techniques instead of simple gradient descents, such as using higher-order derivatives of the weights to affect the error signal, or using extended Kalman filters to estimate appropriate weights. None of these technologies is warranted, and the literature suggests that RNN training works best when it is carefully coached by people with long-term experience. This observation may not be good for the long-term goal of machine learning, such as unsupervised or continuous learning mode. Some applications respond well to different methods. While RNN can retain some of the data selected from previous cycles, there are other types of networks that can access large amounts of RAM or content addressable memory. We can try human analogy. Most people have selective memories and fairly abstract memories. If we ask us to recall the specific details of a scene or event, we usually do not do well. But there are very few people who remember the details, meticulously ordering every item in the room or a random sequence of large numbers. This ability allows these people to solve problems that most of us cannot solve, although they may not have higher reasoning or reading comprehension than others. Similarly, networks that can write or read large blocks of memory or file systems can accurately record large data structures and use them as additional inputs. These networks may have a mixed network structure that is very unlike CNN. For example, hidden layers can perform explicit read and write operations on memory. This actually makes the network a complex way of designing a large state machine (or even a Turing machine): generic, but not necessarily efficient or easy to understand. Again, the existence of large, variable data structures may make training confusing. At its root, the neural networks we have observed so far are really simple: from several layers to many layers, there are relatively few connections between layers (at least less than all interconnected networks), and all signals follow The input to the output flow in the same direction, and each node of the layer has the same function. Only the weights on the connection will be adjusted during training. RNN is more complex just to support backward, facing input, and forward connections. These simple structures do not resemble neurons that physiologists find in mammalian brains. In mammalian cerebral cortex, there are usually about 10,000 connections per neuron. The connection scheme seems to change over time or with learning. Neurons can have many different functions and dozens of neuronal cells have been observed. The signal transmission method is pulse coding instead of voltage level. Currently, researchers are trying to get rid of the simplified functional map of the neural network, closer to the biological reality. These neural networks strike a balance between the amazing biological complexity and the limitations of software simulation and microcircuitry. Therefore, they provide a wealth of interconnections, but still far less than 10,000 axons per neuron. They provide many different neuronal behavioral models, a certain degree of interconnection routing and functional programmability, and weights. It can be simulated in software, but without hardware acceleration, performance and size often limit the complexity of the network that can be explored. The scope of hardware implementation includes everything from digital ASICs and FPGAs to mixed-signal and pure analog custom chips. Many neural networks not only have greater connectivity than traditional deep learning networks, but also have higher interconnection diversity: the connection can not only advance to the next layer, but also stay in one layer or return to the previous layers. The neural network has a pure form, completely abandoning the concept of layers, and becomes a three-dimensional neuron ocean close to any connection (at least in the local neighborhood). The neural network shows capabilities similar to traditional CNNs such as AlexNet in image and speech recognition. But IBM claims that its per-watt frame rate implemented on the TrueNorth Neuromorphic ASIC is several times faster than implementing AlexNet on the NVIDIA Tesla P4. Given the richer interconnections, the possibility of feedback and multiple neuronal functions in neural networks, the artistic significance of training may be greater than the significance of RNN. But the biggest hope for this idea may lie in training. There are some indications that these networks can far surpass the supervised learning models used in commonly used back-propagation. The current typical supervision training is a separate phase during which the coach must provide the correct response for each training input. Training is often an exhausting process and must be completed before the network is put into use. The quality of training greatly limits the accuracy of the network. In addition, there are many other types of training in practical applications. Trainers can only give hints, not give answers: only when the network tends to give an ideal output, instead of propagating the correct answer back for each input frame. The network can also learn by optimizing some statistical functions that define useful behavior. For example, this unsupervised learning may be a network that needs to receive live video of the robot arm and output commands to the arm motor. When you start training the network, you send a random command to the click and observe intermittent results. However, when it learns to establish a correlation between its output and observed results, it is possible to fuse a near-optimal control algorithm. Unsupervised learning provides the human operator with the promise of being free from performing very complex oversight training tasks: combining a set of training input information (image recognition often requires thousands), assigning the correct label for each input information, and then It is sent to the network one by one. But unsupervised learning has also put forward other promises: the network can learn algorithms that are not perceived or understood. It may find classification schemes that are not yet used by humans. The network is fully protected and can continue to learn after deployment, continuously improving and adapting to new inputs. This is the golden goal of machine learning. From the simple statistical analysis that humans can perform with the help of drawings, CNN-like artificial neural networks, networks with internal or external memory, to potentially incomprehensible neural network systems, etc., designers who expect to solve the problems face a large number of alternative technologies. . However, there are few standards used to select appropriate technologies, except for the choices designers have made in graduate schools. Moreover, it is often difficult to avoid the suspicion that the results of network design and training may not be better than the well-known statistical analysis algorithms. Unfortunately, there seems to be more and more evidence that all technologies will not give more or less equal results for a particular problem. They may have different accuracy for specific levels of training, different energy consumption for specific speed rates, very different hardware requirements if they must be accelerated, and very different training requirements. It is important to start by ensuring that you are not trying to solve a problem with a known fixed solution. Especially if the implementation requires hardware acceleration, the focus here is to find a way to be able to retain as much algorithmic flexibility as possible for as long as possible, and to use the rich experience of the design team or its partners as much as possible. The game has not won or lost. This has only just begun. The utility model provides a disposable electronic cigarette, comprising: a hollow shell, the bottom of the shell is provided with a lower cover; the shell contains an atomizer, and the outer side of the atomizer is sheathed with a disposable cigarette A bomb, a microphone cover is arranged under the atomizer, a microphone is covered under the microphone cover, a battery is arranged on one side of the atomizer, and an upper cover is arranged on the top of the casing; The atomizer includes an atomizing core, an oil-absorbing cotton sleeved on the outside of the atomizing core, and an atomizer outer tube sleeved on the outside of the oil-absorbing cotton. The disposable electronic cigarette provided by the utility model absorbs the smoke oil on the surface through the absorbing cotton, and then atomizes the smoke through the atomizing core, which greatly reduces the risk of oil leakage, at the same time, reduces the burning of cotton and ensures the smoking taste.The utility model provides a disposable electronic cigarette, comprising: a hollow shell, the bottom of the shell is provided with a lower cover; the shell contains an atomizer, and the outer side of the atomizer is sheathed with a disposable cigarette A bomb, a microphone cover is arranged under the atomizer, a microphone is covered under the microphone cover, a battery is arranged on one side of the atomizer, and an upper cover is arranged on the top of the casing; The atomizer includes an atomizing core, an oil-absorbing cotton sleeved on the outside of the atomizing core, and an atomizer outer tube sleeved on the outside of the oil-absorbing cotton. The disposable electronic cigarette provided by the utility model absorbs the smoke oil on the surface through the absorbing cotton, and then atomizes the smoke through the atomizing core, which greatly reduces the risk of oil leakage, at the same time, reduces the burning of cotton and ensures the smoking taste.The utility model provides a disposable electronic cigarette, comprising: a hollow shell, the bottom of the shell is provided with a lower cover; the shell contains an atomizer, and the outer side of the atomizer is sheathed with a disposable cigarette A bomb, a microphone cover is arranged under the atomizer, a microphone is covered under the microphone cover, a battery is arranged on one side of the atomizer, and an upper cover is arranged on the top of the casing; The atomizer includes an atomizing core, an oil-absorbing cotton sleeved on the outside of the atomizing core, and an atomizer outer tube sleeved on the outside of the oil-absorbing cotton. The disposable electronic cigarette provided by the utility model absorbs the smoke oil on the surface through the absorbing cotton, and then atomizes the smoke through the atomizing core, which greatly reduces the risk of oil leakage, at the same time, reduces the burning of cotton and ensures the smoking taste. maskking vape,maskking vape price,maskking vape review,maskking vape shop,,maskking vape cost,maskking vape disposable,maskking vape informacion Suizhou simi intelligent technology development co., LTD , https://www.msmsmart.com
Wide range
Specific issues 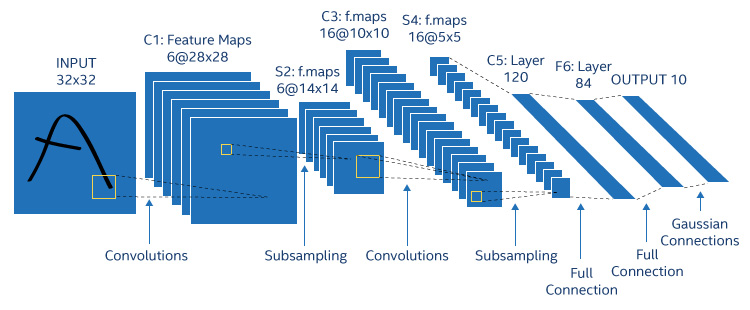
Figure 1. A convolutional network consists of a fixed layer of multiple functions, starting with a simple convolution kernel.
Memory is important 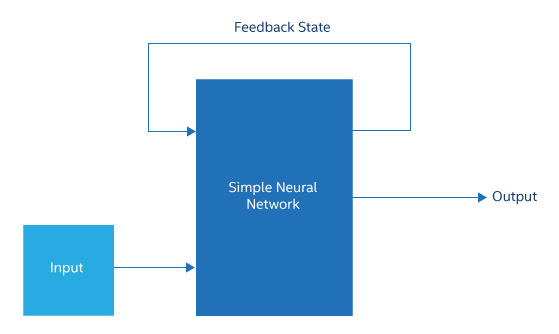
Figure 2. Recurrent neural networks are often simply neural networks that can return intermediate states or output data by inputting data to it.
Memorable RNN
Neuromorphology
Too much choice