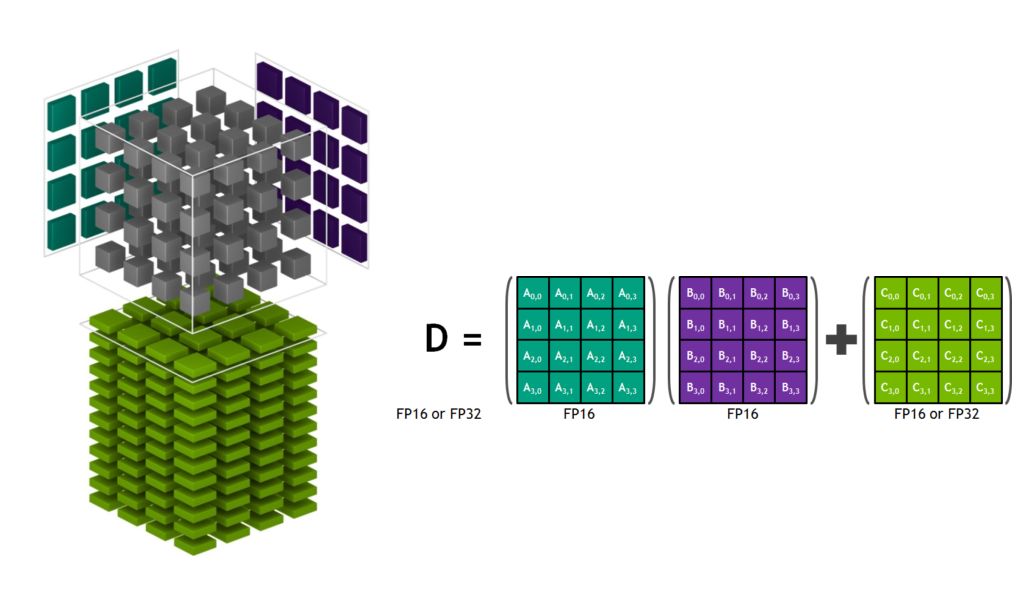
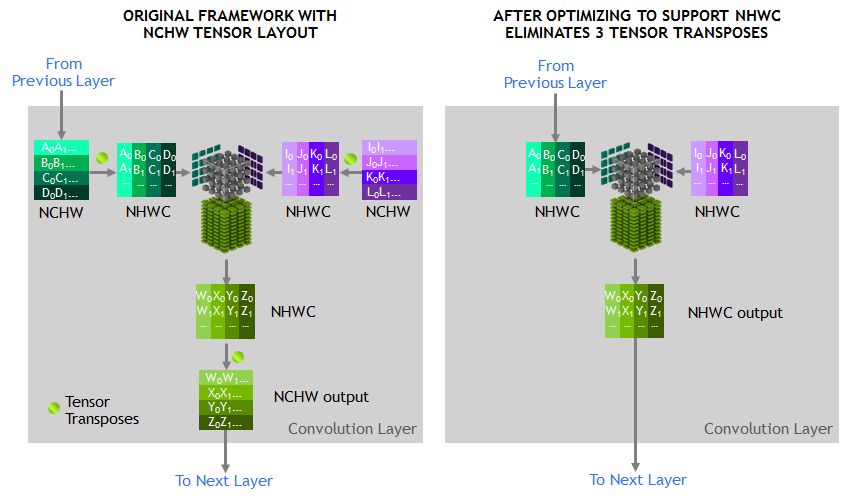
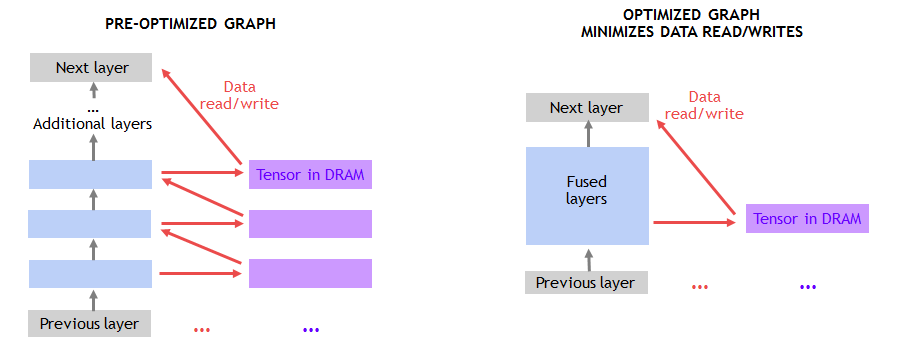
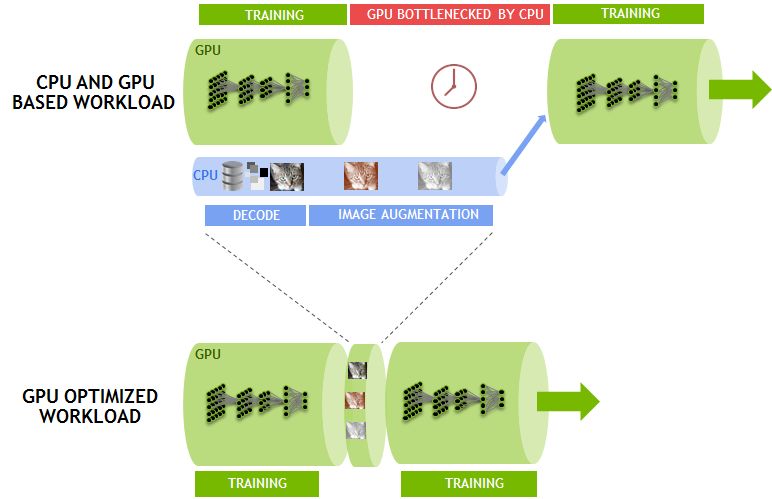
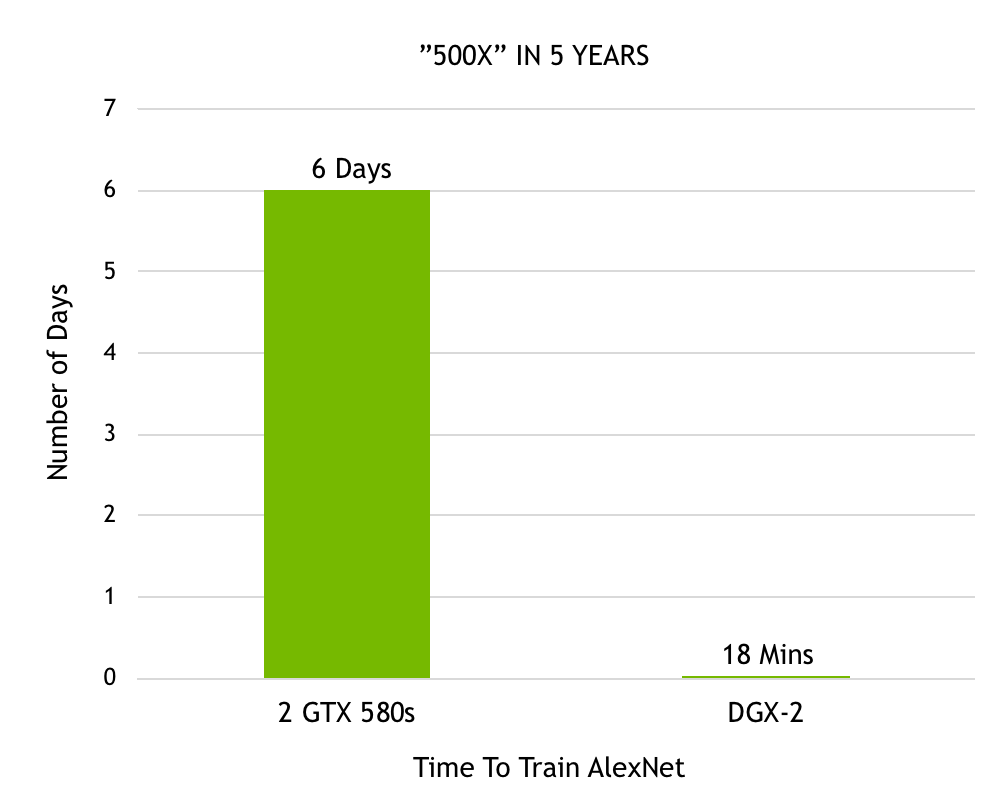
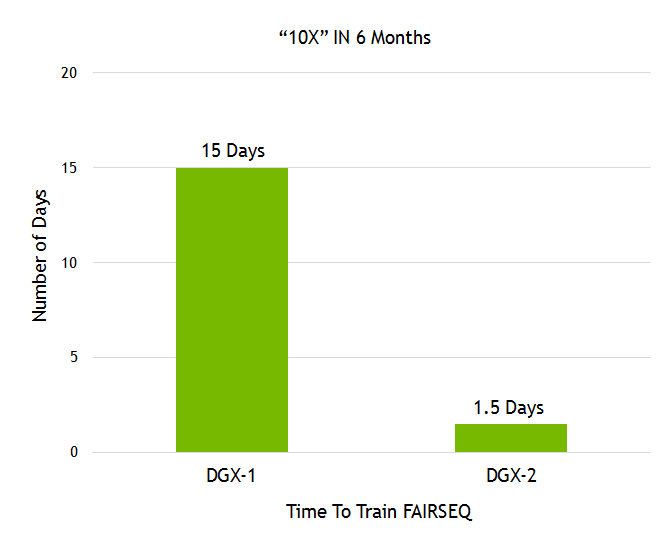
Artificial intelligence based on deep learning can now solve problems that were once thought impossible to solve, such as computer understanding of natural language and dialogue in natural language, automatic driving, and the like. Deep learning has been effective in solving many challenges. Inspired by this, the complexity of the algorithm has also grown exponentially, which in turn has triggered the need for faster computing speeds. NVIDIA designed the Volta Tensor Core architecture to meet these needs. NVIDIA and many other companies and researchers have been working on developing computing hardware and software platforms to meet this need. For example, Google created a TPU (tensor processing unit) accelerator that currently supports running a limited number of neural networks and shows good performance. We will share some recent developments for you, which have brought a huge performance boost to the GPU community. We have achieved new records for single-chip and single-server ResNet-50 performance. Recently, fast.ai also announced record-setting performance on a single cloud instance. Our results show: When training ResNet-50, a single V100 Tensor Core GPU can achieve 1075 images per second, a 4x improvement in performance over previous generation Pascal GPUs. A single DGX-1 server based on eight Tensor Core V100s achieved 7,850 images per second on the same system, almost double the year before (4,200 images per second). A single AWS P3 cloud instance based on eight Tensor Core V100s can train ResNet-50 in less than three hours, three times faster than a TPU instance. Figure 1. Volta Tensor Core GPU achieves record speed in ResNet-50 (AWS P3.16xlarge instance contains 8 Tesla V100 GPUs). The massively parallel processing performance of NVIDIA GPUs based on diverse algorithms makes it a natural choice for deep learning. But we did not stop there. Using our many years of experience and close collaboration with AI researchers around the world, we have created a new architecture optimized for multiple deep learning modes—NVIDIA Tensor Core GPUs. Combining NVLink high-speed interconnection with depth optimization in all current frameworks, we achieved leading performance. The programmability of NVIDIA CUDA GPUs ensures a wide variety of modern network performance while providing a platform to innovate in emerging frameworks and future deep network domains. Create a single processor speed record The Tensor Core GPU architecture built into the NVIDIA Volta GPU is a huge step forward for the NVIDIA Deep Learning Platform. This new hardware accelerates the computation of matrix multiplication and convolution, which is also the focus of computational operations when training neural networks. The NVIDIA Tensor Core GPU architecture enables us to provide higher performance than a single-function ASIC at the same time, but it can be programmed for different workloads. For example, each Tesla V100 Tensor Core GPU provides 125 teraflops of deep learning, while Google’s TPU chip is 45 teraflops. The four TPU chips in the "Cloud TPU" can achieve 180 teraflops of performance; in contrast, four V100 chips can achieve 500 teraflops of performance. NVIDIA's CUDA platform enables each deep learning framework to take full advantage of Tensor Core GPUs, accelerating the expansion of neural network types such as CNN, RNN, GAN, RL, and thousands of variants that emerge each year. Let's take a closer look at the Tensor Core architecture to understand its unique features. Figure 2 shows that Tensor Core stores tensors in the lower-precision FP16, and uses higher-precision FP32 for calculations to maximize throughput while maintaining the necessary accuracy. Figure 2: Volta Tensor Core Matrix Multiplication and Stacking With recent software improvements, ResNet-50 training can now achieve 1,360 images/second on a single V100 in independent testing. We are now trying to integrate this training software into a widely adopted framework as described below. Tensor Core runs a tensor that is located in the memory's channel-interleaved data layout (number-height-width-number of channels, commonly referred to as NHWC) for optimal performance. The expected memory layout of the training framework is the data layout of the channel main sequence (number - number of channels - width - height, commonly referred to as NCHW). Therefore, the cuDNN library performs a tensor transpose operation between NCHW and NHWC, as shown in FIG. As mentioned earlier, these transpositions obviously take up a portion of the run time, as the convolution itself is now so fast. To avoid such transpositions, we eliminate transpose by replacing each tensor in the RN-50 model diagram directly in the NHWC format, which is a feature that the MXNet framework can support. In addition, we added an optimized NHWC implementation for MXNet, adding cuDNN to all other non-convolved layers, eliminating the need for any tensor transposition during training. Figure 3. Optimized NHWC format eliminates tensor transposition Amdahl's law also gives us another opportunity for optimization, which predicts the theoretical acceleration of parallel processing. Because Tensor Core significantly speeds up matrix multiplication and convolutional layers, the other layers in the training load account for a higher percentage of runtime. So we identified these new performance bottlenecks and optimized them. As shown in Figure 4, the transfer of data to and from the DRAM results in the performance of many non-convoluted layers being limited. The practice of merging successive layers can use on-chip memory and avoid DRAM traffic. For example, we created a graphical optimization license in the MXNet to detect successive ADD and ReLu layers and replace them as much as possible by the fusion implementation. Implementing such optimization in MXNet using NNVM (Neural Network Virtual Machine) is very simple. Figure 4. Fusion layer eliminates data reads/writes Finally, we continue to optimize a single convolution by creating additional dedicated cores for common convolution types. Currently, we have optimized this for a variety of deep learning frameworks, including TensorFlow, PyTorch, and MXNet. Based on MXNet-optimized, using standard 90-iteration training schedules, we achieved 1075 images per second on a Tensor Core V100 while achieving the same Top-1 classification accuracy (over 75%) as single-precision training. . This leaves us with a huge room for further improvement because we can achieve 1,360 images/second in independent tests. These performance gains are available in the NVIDIA Optimized Deep Learning Framework container for NGC (NVIDIA GPU Cloud). Fastest single-node speed record Multiple GPUs can operate as a single node for higher throughput. However, scaling to multiple GPUs that can work together in a single server node requires a high bandwidth/low latency communication path between GPUs. Our NVLink high-speed interconnect architecture allows us to extend the performance to 8 GPUs in a single server. Such massively accelerated servers provide comprehensive petaflop-class deep learning capabilities and can be widely deployed in both cloud and on-premises deployments. However, scaling to 8 GPUs can greatly improve training performance, so that other work performed by the host CPU in the framework becomes a limiting factor. Specifically, the pipeline that provides data to the GPUs in the framework needs to significantly improve performance. The data pipeline reads the encoded JPEG samples from disk, decodes them, resizes and enhances the images (see Figure 5). These enhancements improve the neural network's ability to learn, thus enabling more accurate prediction of the training model. Given that 8 GPUs are in the training part of the processing framework, these important operations will limit overall performance. Figure 5: Image decoding and enhanced data pipeline To solve this problem, we have developed DALI (Data Augmentation Library), a framework-independent library for offloading work from the CPU to the GPU. As shown in Figure 6, DALI transfers some JPEG decoding work, resizing, and all other enhancements to the GPU. Performing these operations on the GPU is much faster than the CPU's, so the workload can be offloaded from the CPU. DALI makes CUDA general parallel performance more prominent. Eliminating CPU bottlenecks allowed us to maintain 7850 image/sec performance on a single node. Figure 6: GPU Optimization Workload Using DALI NVIDIA is helping to integrate DALI into all major AI frameworks. The solution also allows us to extend the performance of more than 8 GPUs, such as the recently introduced NVIDIA DGX-2 system with 16 Tesla V100 GPUs. Fastest single cloud instance speed record For our single-GPU and single-node operation, we used the de facto standard of 90 iterations to train ResNet-50 so that its single-GPU and single-node operation accuracy exceeded 75%. However, with algorithmic innovation and hyperparameter tuning, training time can be further reduced, and accuracy can be achieved with fewer iterations. The GPU provides AI researchers with programmability and supports all deep learning frameworks, enabling them to explore new algorithmic approaches and leverage existing methods. The fast.ai team recently shared their excellent results. Using PyTorch, they achieved high accuracy with less than 90 iterations. Jeremy Howard and fast.ai researchers integrated key algorithmic innovations and tuning techniques into AWS P3 instances and completed ResNet-50 training on ImageNet within three hours. The example is powered by eight V100 Tensor Core GPUs. The ResNet-50 is three times faster than the TPU-based cloud instance (the latter takes nearly 9 hours to complete ResNet-50 training). We also expect that the throughput improvement methods described in this paper can also be applied to other research methods such as fast.ai, and can help them to aggregate faster. Provide exponential performance improvement Since Alex Krizhevsky first used two GTX 580 GPUs to win the Imagenet competition, we have made remarkable progress in accelerating deep learning. Krizhevsky spent six days training a powerful neural network called AlexNet, which surpassed all other image recognition methods at the time and opened the deep learning revolution. Now with our recently released DGX-2, AlexNet training can be completed in 18 minutes. Figure 7 shows a 500-fold improvement in performance in just 5 years. Figure 7. Time required to train AlexNet on the Imagnet dataset Facebook AI Research (FAIR) shared their language translation model Fairseq. In less than one year, we have demonstrated a 10X performance increase on Fairseq with the recent release of DGX-2, plus many of our software stack improvements (see Figure 8). Figure 8. The time needed to train Facebook Fairseq. Image recognition and language translation represent only a small part of the countless use cases that researchers have solved with the power of AI. More than 60,000 neural network projects using GPU acceleration framework have been published to Github. The programmability of our GPUs can provide acceleration for the various neural networks that the AI ​​community is building. Rapid improvements ensure that AI researchers can boldly conceive more complex neural networks to cope with the immense challenges with AI. These excellent performance comes from our full stack optimization method for GPU accelerated computing. From building state-of-the-art deep learning accelerators to complex systems (HBM, COWOS, SXM, NVSwitch, DGX), from advanced numerical libraries and deep software stacks (cuDNN, NCCL, NGC) to accelerating all deep learning frameworks, NVIDIA for AI The promise provides AI developers with unparalleled flexibility. We will continue to optimize the entire series and continue to provide exponential performance enhancements to provide the AI ​​community with tools that promote deep learning and innovation. to sum up AI continues to change every industry and promote countless use cases. The ideal AI computing platform needs to provide excellent performance to support a huge and ever-increasing model scale, and also requires programmability to cope with increasingly diverse model architectures. NVIDIA's Volta Tensor Core GPU is the fastest AI processor in the world, providing 125 teraflops of deep learning performance on a single chip. We will soon consolidate 16 Tesla V100s into one server node to create the world's fastest compute server that provides 2 petaflops of performance. In addition to excellent performance, the programmability of the GPU and its widespread use in the cloud, server manufacturers, and the entire AI community will drive the next AI revolution. We can speed up all of the following common frameworks you use: Caffe2, Chainer, Cognitive Toolkit, Kaldi, Keras, Matlab, MXNET, PaddlePaddle, Pytorch, and TensorFlow. In addition, NVIDIA GPUs work with the rapidly expanding CNN, RNN, GAN, RL, and hybrid network architectures, as well as thousands of variations of new debuts each year. The AI ​​community has seen a lot of amazing applications and we look forward to continuing to build on the future of AI.
Zinc wire is a good anti-corrosion material,widely used in steel structure anti-corrosion,wind power tower,bridge,sluice gate,oil pipe on sea,Ductile iron pipe,extrusion division tube.
Zinc Wire,High Pure Zinc Wire,Zinc Wire Mesh,Corrosion Protection Zinc Wire Shaoxing Tianlong Tin Materials Co.,Ltd. , https://www.tianlongspray.com