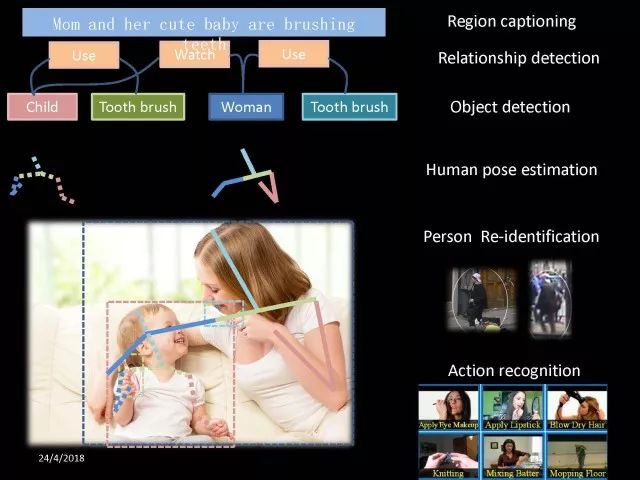
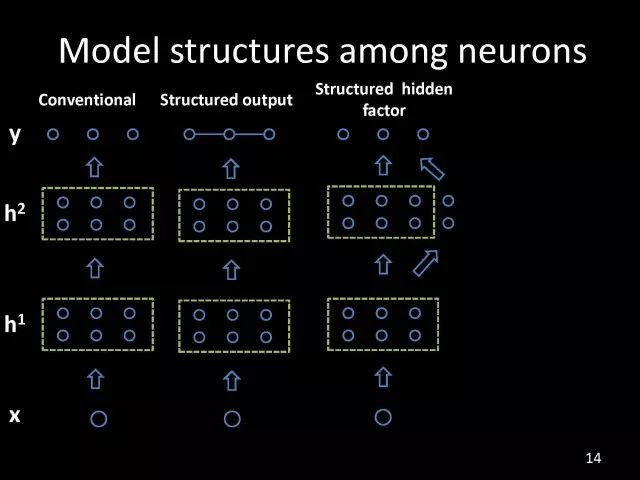
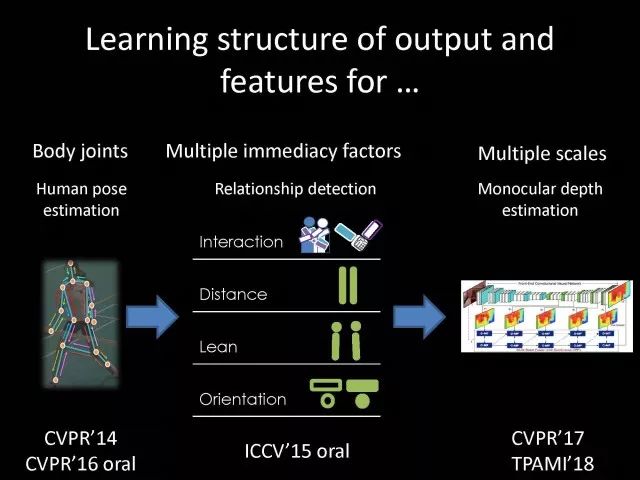
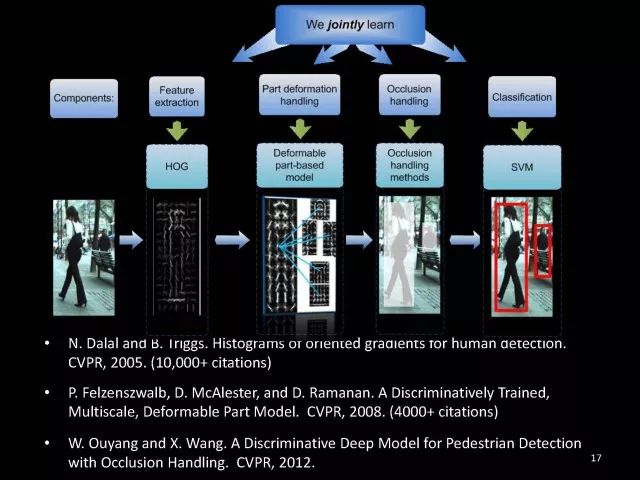
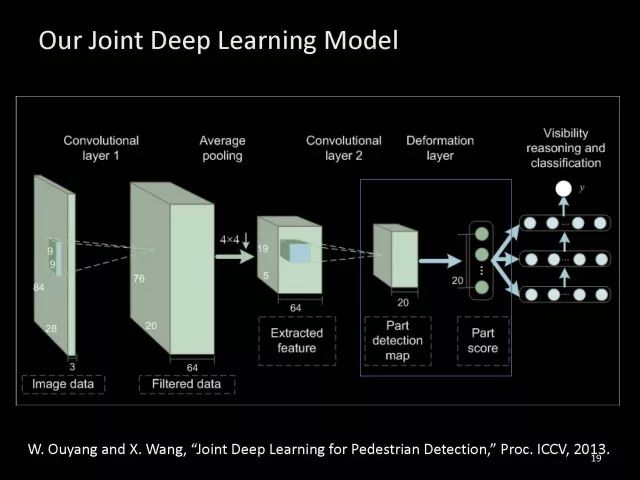
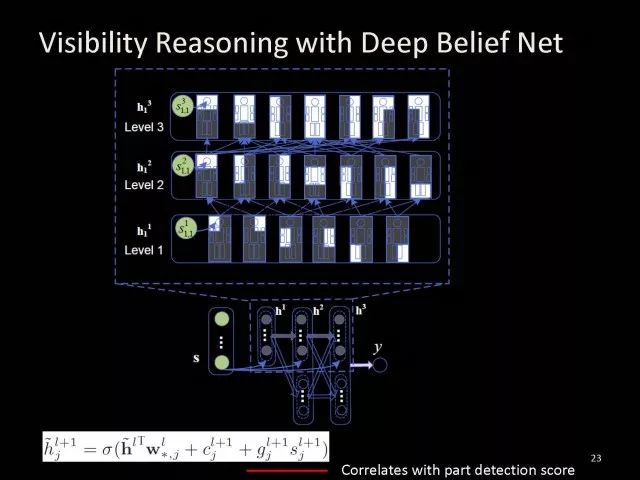
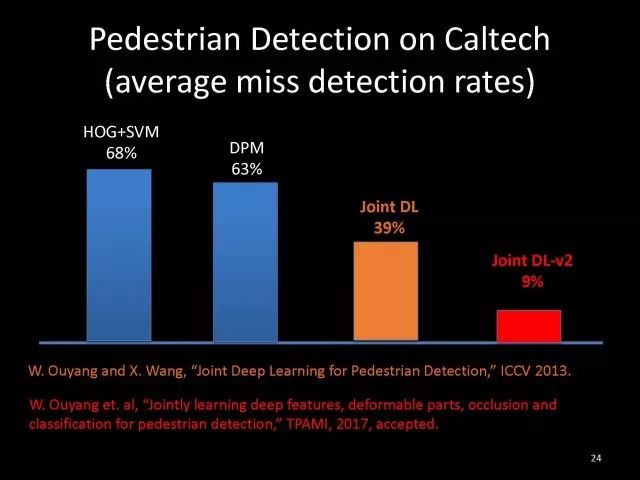
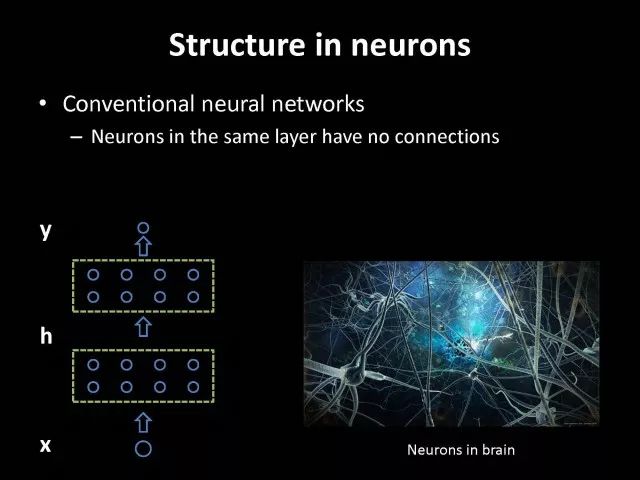
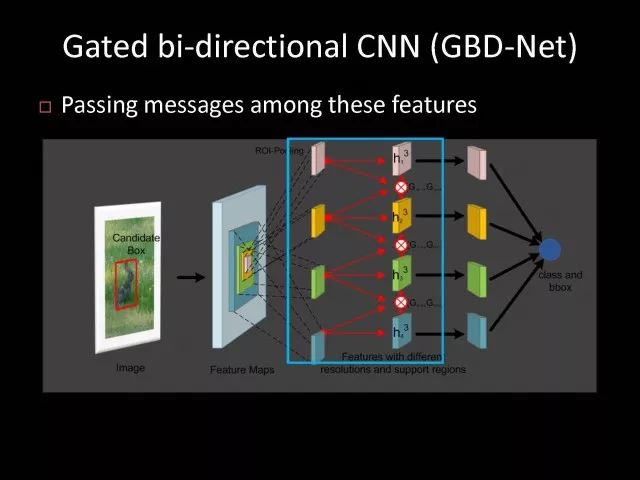
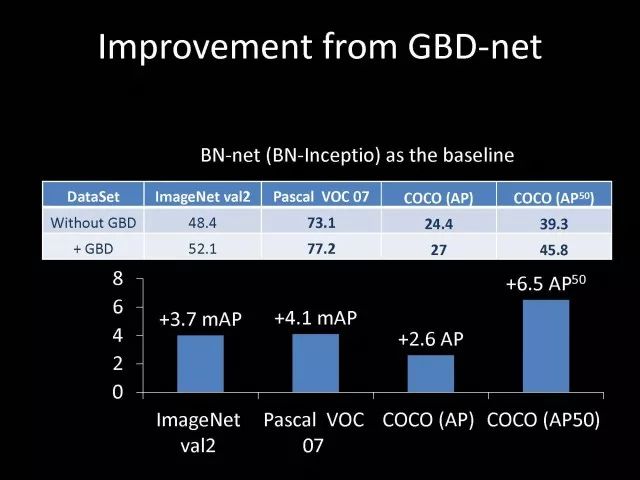
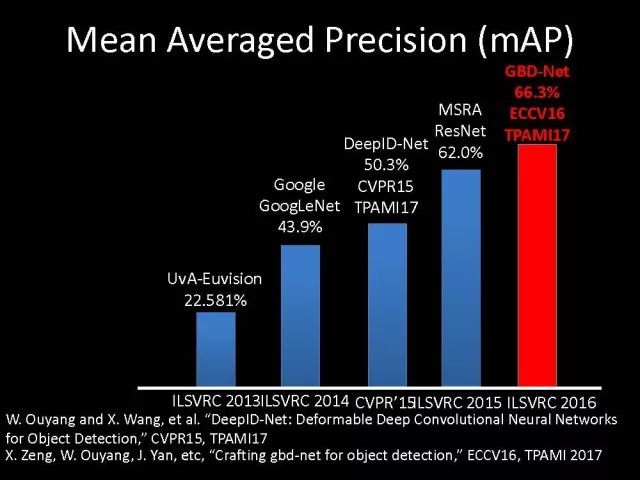
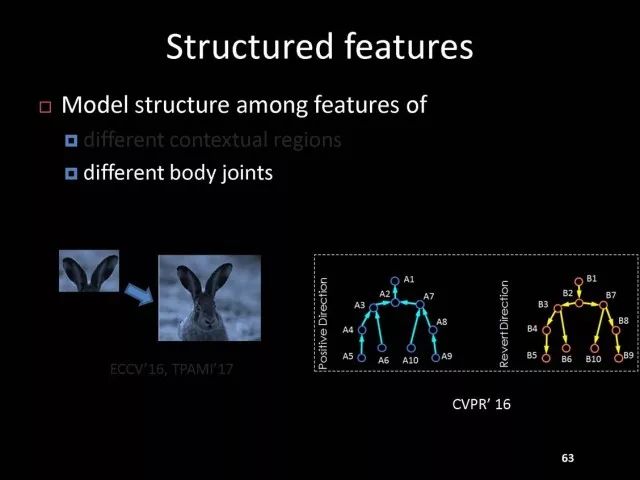
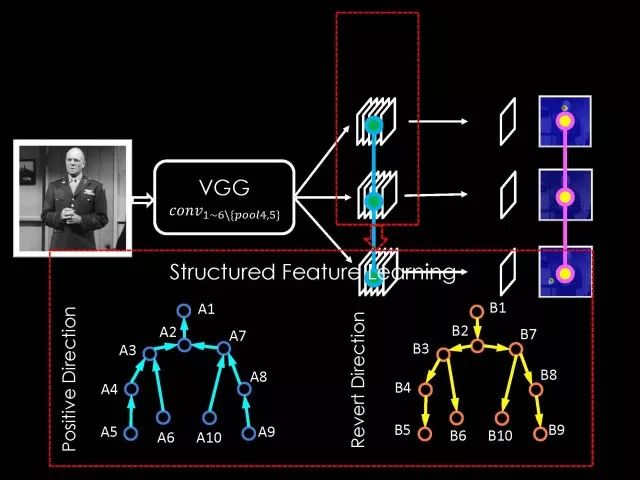
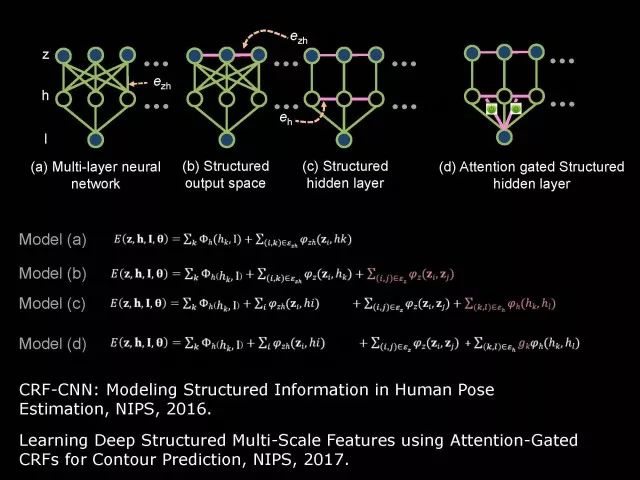
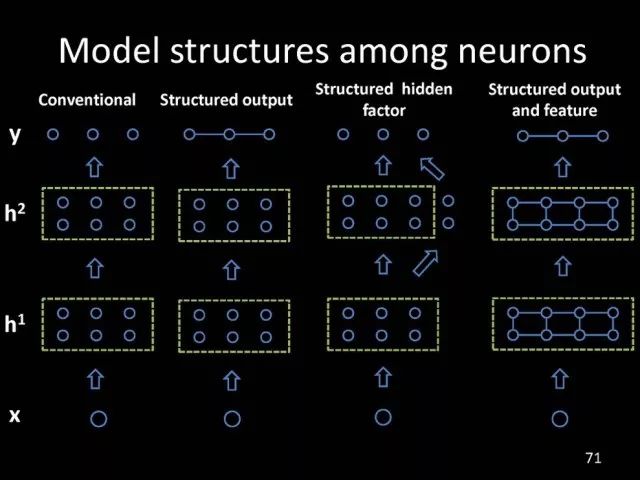
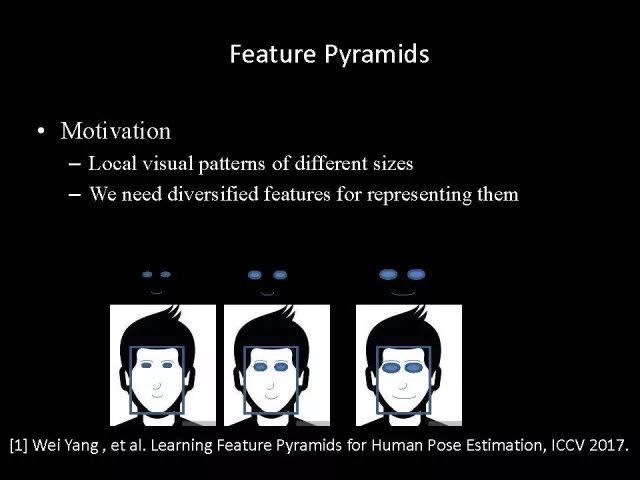
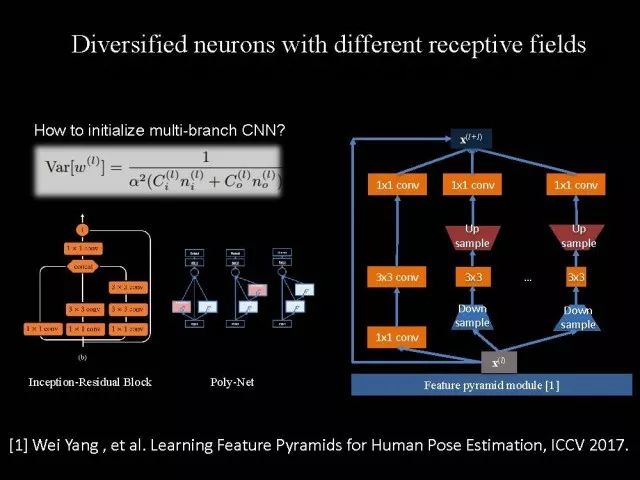
Editor's note: It is rumored that Emperor Huizong of the Song Dynasty had used the “deep mountain Tibetan temple†as a subject to paint, winning the paintings of the princes, and painting in the mountains, a stream of springs flowed down, jade splashes were splashed, and there was a monk in the old style of the fountain. Poured into the bucket with spring water. The beauty of this painting is that the implicit information of the "Temple" is extracted from the known semantic information of "the old monk who fetched the water", thus making the painting the scene. In the field of computer vision, this allusion is showing the importance of implicit information transmission in structured analysis and understanding of the content of the screen. In recent years, deep learning has achieved remarkable results. However, since its submission, questions such as "black box intelligence" and "poor interpretability" have been heard. "Black box intelligence" means that the results cannot be guaranteed. , and it is easy to fall into this deadly problem of "confidence mistakes." Therefore, the world's top laboratories are thinking about the "why" problem and trying to increase the interpretability of the algorithm to open the dark box of deep learning. Today, Prof. Ouyang Wanli from the University of Sydney will use structured modeling to try to get a glimpse of the dark box of deep learning in the field of image understanding. In this report, I introduce the work I have done at the Chinese University of Hong Kong and at the University of Sydney with many teachers and students. First of all, let's take a look at the work related to detection and human posture recognition. Given an image, determine the position of the object of interest in the picture, such as the woman's toothbrush, this is the object detection work. The further analysis of the target detection is the relationship detection. After getting the relationship, you can do more semantic understanding, such as using a sentence to describe its semantics in a certain area of ​​the picture, such as the mother and the adorable child brushing their teeth. After the object is detected, the semantic information can be gradually taken upwards, and the object of interest can be further analyzed, for example, the key points of the human body can be positioned, that is, the human posture recognition. With these object detection and posture detection, you can analyze pedestrians and analyze people's movements. The key point location and identification tasks have many difficulties. For example, people may wear different colors of clothes, they will be blocked, the body will change flexibly, and the visual information will change due to deformation. To handle visual information well, we introduce structured learning. Learning to output structured information is an important part of our process of opening deep learning black boxes. We expect to use the understanding of the problem to help us get more improvement on the results that deep learning can achieve. We have some work on the modeling of structured output. For example, in the human pose recognition task, the spatial structure relationship between key points of the human body can be modeled. For human interaction, there may be many interactive factors, such as interactions, specific to embracing, hand in hand. Other interaction factors, such as the distance between people, inclination, orientation, etc., also have a positional relationship between them, so they can be structured and modeled. Based on the monocular camera to get the depth information prediction task, we can use the convolutional network to help us obtain different depth information predictions in different resolution features. There are also many correlations between them, and they can be structured and modeled. The latest work considers different modalities. It is not the same person who compares two pictures in the cross-camera search information. Structured information can be used to help us model the segmentation of multivalued information. In the case of further opening the deep learning black box, we can introduce the factors that the label or output does not have, and continue to jointly learn the modeling of the characteristics and the learning of the depth characteristics. The specific example is object detection. We will encounter changes in occlusion and human deformation. These factors are all implicit. There is only one rectangular box in the tag. There is no such information. If we can design a method that requires very few parameters to be able to reason about implicit factors, it can actually help the model learn better features and achieve better results. For example, with an image, we can use a deep learning model or already manually designed features to process it. An implied factor in this task is deformation. We can introduce a model for dealing with deformation and learning deformation. A famous model is the deformable part model. Another hidden factor is occlusions, such as the person's leg being blocked by a chair in this picture. If you can reason about the block of the human body, you can find out some of the sheltered parts, do not use the chair to be blocked to learn the visual shape of the human leg. If you can get such hidden factors can further improve the detection effect. The last is sorting. Learning between these modules is a fixed part of the parameters of the previous part, learning the final parameters, the lack of communication between each module. We can design a joint deep learning model and combine these modules so that each parameter can be communicated very well, so that each module can communicate with each other to learn better models to improve accuracy. This is how we design the basic model. First we use the convolutional network to help us learn the features. With the features, we can use the deformation layer to learn the deformation of various parts of the body. Suppose there is a detector that can detect the position of a person's shoulder in the picture. One example of a detector is such a shoulder. If the shoulder detector is slidingly matched in the picture, such a response map will be obtained. Where there is no shoulder, there is a high response that we don’t want. If we use these areas to learn what people’s shoulders are, the traits are not good, and the detectors on the shoulders are not good at learning. In order to deal with this problem, we can use the characteristics of deformation. We can take into account that people's shoulders do not run from the corresponding position to the lower right corner of the person, so we design the map of deformation and automatically learn the deformation characteristics of the person. Translate this probabilistic description into a map, and add the corrected map. If you use the corrected map to detect, you can accurately locate where the deformation is, and you will get better results with respect to features and detection learning. On the other hand, various parts of the human body are obstructed and detectors of different body parts are involved. For example, with respect to human left and right leg detectors, if two detectors are blocked and both legs are blocked together, the relationship between different detectors can be learned with deep belief net. We conducted some experiments. In 2013, the largest pedestrian detection database, the use of manual design features plus the existing classifier error rate was 68%. If the factors that deal with the deformation implicature can be reduced to 63%, the combination of feature learning, and deformation and occlusion joint learning can reduce the error rate to 39%. If we further use better depth learning, the recent work error rate can be reduced to 9%. Paper related code at the following address: Http://~wlouyang/projects/ouyangWiccv13Joint/index.html. The above-mentioned learning of the two hidden factors of deformation and occlusion is mainly used in individual pedestrian detection work. We will expand it. The first expansion is to expand the learning of deformation into universal object detection. We have developed a new deformation learning model. This work was published in PAMI in 2017 and has been one of the most popular articles in TPAMI for several months. Another extension is to apply the inference of the visibility and invisibility of individual pedestrians to two pedestrians. When they are occluded from each other, there is a visible blend of incompatibility and incompatibility between them, thereby increasing mutual occlusion. The effect of the situation. The above introduction is that we use the implicit factors to specifically study the deformation and occlude two hidden factors. We learn the parameters of these two hidden factors and learn the characteristics of deep learning in a joint learning, so as to improve the effectiveness of our specific tasks. In order to further open the deep learning black box, we consider the structural modeling between the features. Its motivation comes from another observation. Fully connected networks or convolutional networks have a common feature in that neurons are not connected in the same layer, but not in the human brain. There is a connection between neurons in the same layer in the human brain. With respect to deep learning, the most important information for researchers is to design good learning methods and good model design methods, making the model deeper and deeper. Is it the only way out for us to deepen our model? Another question is whether the visual researcher can help with the observation and understanding of the problem. To answer this question, we designed GBD-Net. GBD-NET uses contextual information to help us identify what the object of interest is. Computer vision researchers have long known that contextual information is helpful for identifying objects. How do you consider contextual information when you have a deep learning model? We consider the relationship between features that can learn different contextual information. For example, there is now a feature that corresponds to the rabbit's ear. It is less contextual information and it can be assumed that there should be a rabbit's head below. Therefore, the rabbit's ears have less contextual features and the rabbit's head has more contextual features, and vice versa. It can be seen that the characteristics of different contextual information can be mutually verified. On the other hand, if you see a rabbit's ear, you don't necessarily have the rabbit's head underneath, as shown in the counter example above. In this case, if we see the following is not a rabbit's head, but a person's face, we hope that the rabbit's ears do not pass information to the rabbit's head. Therefore, information needs to be transmitted, but the transmission of information needs to be controlled. Based on the existing inspection network, we designed GBD-Net. It uses the existing network structure to get different context features. With different contextual information features, information transfer begins. Information can be passed from top to bottom, that is, features with less contextual information are passed to features with more contextual information. It is also possible to reverse the transfer, that is, to pass features with more context information to features with less context information. We combine the two sets of features passed in different directions and introduce a function to help us control the transmission of information. After the information is passed, these features will be corrected. We use the modified features to help us perform the final inspection task. Experiments have found that in different databases and different network structures, the use of information transfer methods between our characteristics can be very effective. We used this method to participate in the 2016 competition and we won the first place in static object detection and dynamic video object detection tracking. Summarize GBD-Net. The first point, the characteristics are still important. Second, visual workers are equally important to the observation and analysis of problems based on professional knowledge. Third, we use deep learning as a tool to help model the relationships between features. Specifically, we designed GBD-Net to transfer information between different context features. Paper related code can scan QR code. What was just done in object detection is whether the structural modeling between the features is only suitable for object detection? This is not the case. It is also effective in many other tasks. For example, in human posture recognition, we consider that each key point of the human body is a feature in which information can be transmitted. A set of features corresponding to each key point can be considered. After corresponding features are available, the corresponding features can be considered as nodes. After the nodes, the key tree structure of the human body can be taken into consideration. Each node of the tree structure can be considered. Between the information transfer. Paper related code in: https://github.com/chuxiaoselena/StructuredFeature. What we have just introduced is still such features with similar semantic information. In fact, such features do not necessarily have the same semantics. In specific work, it can be considered that these features can have different semantic information. For example, the object detection may have characteristics specifically corresponding to each object, such as the lady's own characteristics, and also has its own characteristics for the toothbrush. The child and his toothbrush have their own characteristics, and go up and go between different objects. Relationships also have a set of features that specifically identify object relationships. Going on, each statement also has its own characteristics. If you consider that each feature is a node, you can still use the relationship between them, generalize the information transfer, and ultimately improve the effectiveness of these three different tasks. The above describes the use of structured information transfer to perform structured information modeling on different tasks. The problem it faces is that there is no theoretical guidance for information transfer. We have only designed it through observation and found out through experiments that it is effective. To solve this problem, we introduce a statistical model. Specifically, we introduce conditional random fields to help us design the network structure. The network structure conforms to such a statistical model. In the specific work, we modeled the conditional random field of information transmission and utilization between features, and also modeled the characteristics of information transmission and utilization conditions added to the threshold control. Under the guidance of the statistical model, another advantage can be to use a good information transfer method in the statistical model to help guide us how to transfer information between nodes is the most effective. Therefore, for structured information delivery, structured output can be taken into consideration on an existing basis, and structural features can be introduced to enable structured learning and structured output to be jointly learned. In addition to structured learning, we have done a lot of work in the basic network design of our laboratory. Lin Dahua has designed a very good network, PoLyNet, which is a very deep network structure. The basic idea of ​​this network structure is to introduce multiple inception modules in the same module, which can be parallel or serial. Using this method, Dahua's students took part in the 2016 competition, in which the individual model results were the best at the time. Another motivation for work is if there are faces of the same size, but the local features are not the same. For example, in this example there are three faces of the same size, but the size of the visual information of the person's eyes and mouth is not the same. This requires that our neurons have diversity to capture these different sized features. In order to capture features of different sizes, there is a design that is to design filters of different sizes or to superimpose filters of different sizes. For example, if there are 3×3 stacks, you can get 5x5, which will increase the amount of parameters. And computational complexity. Another way we consider is downsampling. No downsampling is used in the first branch. In this case, the visual information corresponding to the 3×3 convolution is the size of 3×3. If the other branch uses 2 downsampling, the feature will become 1/2. The size of 3×3 convolutions is 6×6. In this way, only changing the downsampling parameters can help us achieve the purpose of capturing different size features. Ultimately, we use uptake operations to make downsampling features of different size and resolution into the same size to facilitate their connection. Downsampling and upsampling do not require parameters, which are fast. This practice has achieved good experimental results. Paper related code in: https://github.com/bearpaw/PyraNet. Another problem, we have recently proposed a variety of network structuring, such as ResNet, DenseNet, ResNext, and even like GoogleNet and our design of PolyNet, these networks have one thing in common: It has multiple branches. One problem is that the basic assumptions of commonly used parameter initialization methods are not valid for a network structure with multiple branches. If you initialize with such parameters will bring some problems. In order to solve this problem, we carry out strict theoretical derivation and give the final answer. Derivation findings are related to input and output branch counts and parameter initialization. In image classification and human posture recognition, we find that using our method will get better results. The other is human behavior identification. Behavior identification and much of the information that is important in video tasks is exercise. If we want to get information about the movement, we find that there is a very simple operation, that is to get two frames of image features, and to subtract the two feature point-element-wise. This subtraction is a gradient in time, and the spatial gradient can be obtained with a very simple operation. This simple operation derives from the derivation of our mathematics. The derivation of mathematics tells us that the representation of such features and the optical flow are orthogonal, and orthogonal means that they are complementary. This feature will have the original optical flow. No information. Experiments have found that we can achieve similar accuracy using this feature without using optical flow, but it can be much faster in speed. In addition, since the feature is complemented by it, the combination of features can further improve the accuracy. The paper related code will be provided in the near future. To sum up, structured deep learning is effective in many visual tasks. Structured information is usually derived from observations and comes from the understanding of the problem. The observation and understanding of specific issues by researchers in the visual field can be combined with deep learning to advance the entire vision. In addition, we can model the output and features in a structured way. The ability of a tool such as deep learning to provide the ability to combine structural modeling and learning of features to increase the ability to ultimately resolve tasks. Led Membrane Switch,Membrane Switch With Led ,Led Light Membrane Switch ,Membrane Switch With Lcd Display CIXI MEMBRANE SWITCH FACTORY , https://www.cnjunma.com