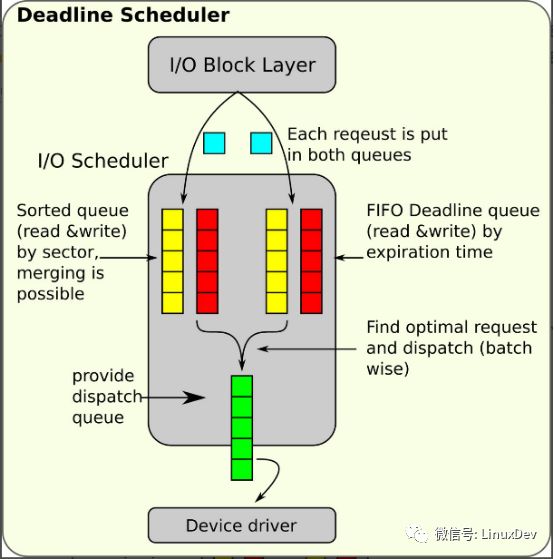
Deadline Introduction Deadline is one of the four IO elevator dispatchers built into the common block layer of the linux kernel. The other three are noop (no operation), cfq (completely fair queuing), and as (anticipatory scheduling). The noop is an empty one. The scheduler only forwards IO requests directly and does not provide sorting and merging functions. It is suitable for fast storage devices such as ssd and nvme. The deadline scheduler was written for the first time by general-purpose maintainer Jens Axboe in 2002 and merged into the kernel during the same period. Since then, it has undergone little modification and has been forever stable. It is now the default IO scheduler for common block-level single queues. Deadline Compared with other elevator schedulers, considering the throughput and latency of IO requests, it should be reflected in the following three aspects: ü Elevator ü Starvation ü time-out The analysis of each property will be described later in detail. Test data shows that the performance of deadline in most multi-threaded application scenarios and database application scenarios is better than cfq and as. Common Block Level Scheduler Framework The kernel common block layer comes with four types of IO schedulers. Each block device is assigned a scheduler at the time of registration. When the block device is running, it can dynamically adjust the scheduler used by the current block device through the /sys interface. Of course, if you like, you can also implement an IO scheduler that meets your needs and register to the common block layer according to the interface standard. In order to satisfy the expansion of the scheduler, the common block layer facilitates the management of various schedulers and refines a unified framework called the elevator framework. Each scheduler only needs to implement the hook function of its own scheduling strategy according to the framework's criteria, and then register itself with the elevator framework. The subsequent block device can use the registered scheduler. The kernel uses a lot of programming techniques to separate design and implementation. Developers who are familiar with the kernel md (multi device) subsystem should understand this method well. The md subsystem standardizes a unified interface, and then various characterization raids implement these. Interface and register itself with the md layer. The interfaces included in the elevator scheduler framework are defined by the struct elevator_ops structure in include/linux/elevator.h under the kernel source code. Each scheduler can implement only some of the interfaces according to its own characteristics. There are four basic interfaces: Elevator_init_fn: The scheduler initializes the interface and is invoked when registering to initialize the scheduler's private data structure; l elevator_exit_fn: The scheduler exits the interface and is invoked when deregistering to release the requested data structure. l elevator_add_req_fn: scheduler entry function, used to add IO requests to the scheduler; l elevator_dispatch_fn: scheduler exit function, used to dispatch the IO requests in the scheduler to the device driver; Deadline implementation principle The deadline scheduler implements the interfaces: Static struct elevator_type iosched_deadline = { .ops.sq = { .elevator_merge_fn = deadline_merge, .elevator_merged_fn = deadline_merged_request, .elevator_merge_req_fn = deadline_merged_requests, .elevator_dispatch_fn = deadline_dispatch_requests, .elevator_add_req_fn = deadline_add_request, .elevator_former_req_fn = elv_rb_former_request, .elevator_latter_req_fn = elv_rb_latter_request, .elevator_init_fn = deadline_init_queue, .elevator_exit_fn = deadline_exit_queue, }, .elevator_attrs = deadline_attrs, .elevator_name = "deadline", .elevator_owner = THIS_MODULE, }; These interfaces inform the scheduler framework of the scheduler's external exposure methods when the scheduler is registered. In addition to the externally exposed interfaces, the internal data structures in the deadline are used to quickly save and manipulate IO requests, such as red and black trees. Lists and so on. These data structures are used internally by the deadline and can be collectively referred to as scheduler scheduling queues. They are not visible to the outside world and require the interface of the scheduler to operate. Struct deadline_data { Struct rb_root sort_list[2]; Struct list_head fifo_list[2]; Struct request *next_rq[2]; Unsigned int batching; /* number of consecutive requests made */ Unsigned int starved; /* times reads have starved writes */ Int fifo_expire[2]; Int fifo_batch; Int writes_starved; Int front_merges; }; To understand the deadline scheduler from an object-oriented perspective, consider the deadline as an encapsulated class. The interface described above is the method of this class. The data structure described above is the data member of this class. The deadline_init_queue is the constructor of this class, which is called when the scheduler is allocated to the block device queue. The user initializes the data member of the class. The deadline_exit_queue is equivalent to a destructor, which is used to release resources requested when the scheduler is instantiated. Other interfaces include adding IO requests to the scheduler's internal data structure, dispatching IO requests from within the scheduler, and merging a bio to a request internal to the scheduler. The two most important members of the deadline scheduling queue are: l struct rb_root sort_list[2]; l struct list_head fifo_list[2]; The sort_list is two red and black trees used to sort the io requests by the starting sector number. The elevator scan of the deadline is based on the two red and black trees. There are two trees, one read request tree, and one The write request tree acts on reads and writes, respectively. Fifo_list is an ordinary first-in-first-out chain, and there are two, corresponding to read and write. Each IO request will be assigned a time according to the current system time and timeout time when entering the scheduler. Then it will be added to the read or write fifo_list according to the IO direction. The fifo_list header will store the IO requests that will be timed out. The scheduler is When the IO request is dispatched, it will check whether there is an IO request that has timed out in the fifo_list. If so, it must be dispatched. This is the literal meaning of the deadline. Each IO request has a deadline for the death line, and read and write timeouts. The time is defined by the fifo_expire member. The default read is 500ms and it is written as 5s. Therefore, the read priority is higher than the write, because the read request is synchronous in most cases and needs to be satisfied as soon as possible. The working process of the deadline scheduler is: The common block layer submits the IO request to the deadline through the registered operation interface of the deadline. After receiving the request, the deadline queues the request in the sort_list according to the requested sector number and gives each request at the same time. Add the timeout period and insert it into the end of the fifo_list. An IO request is attached to both sort_list and fifo_list. When the common block layer needs to dispatch an IO request (flooding or direct IO), it also calls the elevator distribution interface registered by the deadline. When an IO request is dispatched by the deadline, it will comprehensively consider whether the IO request times out, whether the hunger is triggered, and whether it is satisfied based on the elevator algorithm. The batch condition determines which IO request is sent in the end. After the dispatch, the IO request is deleted from both sort_list and fifo_list. The entire process of the deadline service is driven by the common block layer, in other words the deadline is passive and no work queue or worker thread is provided in the kernel. Deadline IO request addition Deadline's scheduling queue (data structure) is a request request. This series of articles "Linux general block layer introduction (part1: bio layer)", "Linux general block layer introduction (part2: request layer)" introduced from the macro How bio requests are converted into request requests and added to the scheduler's dispatch queue, how to merge existing request requests (including requests in the plug list and requests in the dispatch queue). For the deadline, the merging and ordering of IO requests is done in the process of requesting to add to the dispatch queue of the deadline. The bio request enters the deadline queue with two paths: Bio is added to the dispatch queue via the deadline_add_request interface The form of the deadline_add_request interface parameter is request, bio will apply for a new request at the common block layer or merged into the existing request in the plug list, and finally call the deadline_add_request to add to the dispatch queue. /* * add rq to rbtree and fifo */ Static void Deadline_add_request(struct request_queue *q, struct request *rq) { Struct deadline_data *dd = q->elevator->elevator_data; Const int data_dir = rq_data_dir(rq); Deadline_add_rq_rb(dd, rq); /* * set expire time and add to fifo list */ Rq->fifo_time = jiffies + dd->fifo_expire[data_dir]; List_add_tail(&rq->queuelist, &dd->fifo_list[data_dir]); } The interface is very simple, first determine the IO direction of the request, according to the IO direction through the deadline_add_rq_rb the request is added to the read/write red-black tree, the request in the red and black tree with the requested start sector as the node key value, can be directly considered The request in the red-black tree is arranged in the direction of increasing sectors. Then add a timeout to the request, according to the IO direction added to the end of the first-in-first-out chain, fifo_list in the same IO direction of the request has the same fifo_expire, so the first added request first time out, each time added from the tail, So the header's request first times out. This is where the fifo_list name comes from. Bio request merged into the dispatch queue via the deadline_merge* interface In "Linux general block layer introduction (part2: request layer)" we introduced the general block layer blk_queue_bio interface, which has a section of code: Static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio) { ... Switch (elv_merge(q, &req, bio)) { Case ELEVATOR_BACK_MERGE: If (!bio_attempt_back_merge(q, req, bio)) Break; Elv_bio_merged(q, req, bio); Free = attempt_back_merge(q, req); If (free) __blk_put_request(q, free); Else Elv_merged_request(q, req, ELEVATOR_BACK_MERGE); Goto out_unlock; Case ELEVATOR_FRONT_MERGE: If (!bio_attempt_front_merge(q, req, bio)) Break; Elv_bio_merged(q, req, bio); Free = attempt_front_merge(q, req); If (free) __blk_put_request(q, free); Else Elv_merged_request(q, req, ELEVATOR_FRONT_MERGE); Goto out_unlock; Default: Break; } ... } The meaning of this code is to try to incorporate bio into the existing request in the elevator scheduling queue. First, call elv_merge->deadline_merge to determine which combination (see "Linux general block layer introduction (part2: request layer)" The merge type), if it can be merged, the corresponding merge according to the merge type, the function of bio merge to request is completed by the bio_attempt_front_merge/bio_attempt_back_merge interface of the common block layer. For the deadline IO scheduler, the request is in the red-black tree with the start sector as the key value. If it is a forward merge, it will change the starting sector number of the merged request, so the bio merge needs to be called after the merge. Elv_bio_merged->eadline_merged_request to re-update the key value and position of the request in the red-black tree. No matter if it is a forward merge or a backward merge, it is possible to trigger an advanced merge. Attempt_front/back_merge->deadline_merged_requests is called once to handle this advanced merge. The process is to call the merge_remove_request interface to merge the requested requests from the sort_list and fifo_list. In the delete, simultaneously update the timeout of the merged request. Deadline IO request dispatch The core idea of ​​the deadline scheduling algorithm is contained in the request dispatch interface. The interface code is relatively concise, the logic is clear, only one request is dispatched for a single invocation, the dispatching data structure records the dispatched context, and the elevator is fully weighed during scheduling. , hunger, and time-out. /* * deadline_dispatch_requests selects the best request according to * read/write expire, fifo_batch, etc */ Static int deadline_dispatch_requests(struct request_queue *q, int force) { Struct deadline_data *dd = q->elevator->elevator_data; Const int reads = !list_empty(&dd->fifo_list[READ]); Const int writes = !list_empty(&dd->fifo_list[WRITE]); Struct request *rq; Int data_dir; /* * batches are currently reads XOR writes */ If (dd->next_rq[WRITE]) Rq = dd->next_rq[WRITE]; Else Rq = dd->next_rq[READ]; If (rq && dd->batching < dd->fifo_batch) /* we have a next request are still entitled to batch */ Goto dispatch_request; /* * at this point we are not running a batch. select the appropriate * data direction (read / write) */ If (reads) { BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[READ])); If (writes && (dd->starved++ >= dd->writes_starved)) Goto dispatch_writes; Data_dir = READ; Goto dispatch_find_request; } /* * there are either no reads or writes have been starved */ If (writes) { Dispatch_writes: BUG_ON(RB_EMPTY_ROOT(&dd->sort_list[WRITE])); Dd->starved = 0; Data_dir = WRITE; Goto dispatch_find_request; } Return 0; Dispatch_find_request: /* * we are not running a batch, find best request for selected data_dir */ If (deadline_check_fifo(dd, data_dir) || !dd->next_rq[data_dir]) { /* * A deadline has expired, the last request was in the other * direction, or we have run out of higher-sectored requests. * Start again from the request with the earliest expiry time. */ Rq = rq_entry_fifo(dd->fifo_list[data_dir].next); } Else { /* * The last req was the same dir and we have a next request in * sort order. No expired requests so continue on from here. */ Rq = dd->next_rq[data_dir]; } Dd->batching = 0; Dispatch_request: /* * rq is the selected appropriate request. */ Dd->batching++; Deadline_move_request(dd, rq); Return 1; } The elevator of deadline The most important attribute of the elevator scheduler is to keep IO requests dispatching requests in the direction of adapting to the movement of the head arm, so as to reduce the seek time of the IO requests on the disk as much as possible and improve the IO processing capacity, similar to the elevator movement algorithm. It is possible to reduce the moving distance to improve the operating efficiency. This is why the IO scheduler is called the elevator scheduler. Hard disk read and write principle This post describes in detail the principle of disk construction and why IO scheduling is required. The elevator nature of deadline is achieved through a batching mechanism. In the foregoing, the IO request has been sorted in the red-black tree, and the deadline will be sorted in the red-black tree after each deadline. The request (if any) is temporarily stored in the next_rq member, and the request in the next_rq member is dispatched the next time the deadline_dispatch_requests is called again, and the next_rq is updated in the order of the red-black tree. If you consistently distribute according to this idea, the requests in the opposite IO direction may not be responded for a long time, and the requests in the same IO direction may also time out. Therefore, the mechanism for dispatching requests in the order of red-black trees must have a limit. The batching and fifo_batch in the deadline are used for this purpose. Each time the order is dispatched, the batching is incremented by one. If the batching exceeds the fifo_batch (default 16), Need to consider other distribution factors, such as the request timeout, fifo_batch set over the General Assembly to increase the throughput of IO requests, increase the delay of IO requests, and vice versa. This kind of batch distribution with the IO direction is called a batch mechanism. This batch mechanism may end prematurely, for example, there is no IO request that can continue to be distributed in the IO direction. The hunger of deadline The starvation of deadline is to write hunger. The reason why hunger is written is that deadlines give higher priority to IO requests in the read direction. That is, priority is given to read requests. This is because read requests are generally synchronized from a practical application perspective. The higher priority given to reading helps improve the user experience. Always always prioritizing read requests will inevitably result in starvation of write requests. Deadline introduces starved and writes_starved member variables to prevent write starvation. Each time a read request is processed, the counter starved plus one, once starved reaches the threshold writes_starved (default 2 If there is a write request, the next time it dispatches, it will send a write request. Considering the deadline's bulk mechanism, by default the write request yields a maximum of 16 * 2 = 32 read requests. Deadline timeout The starvation of the deadline only affects the direction in which the IO request is dispatched, and the evacuation and timeout of the deadline determine which IO request is dispatched. As mentioned earlier, each request that enters the scheduler is hooked into the fifo_list according to the timeout. The header of the request first times out, and the tail of the request times out. After processing a batch of requests, the deadline will determine if there is a request timeout in the IO direction based on hunger. If there is a request for timeout, the request will go to the request (fifo_list header request). If there is no request timeout yet, and the next_rq in the same direction has a temporary request, the request in the next_rq is continued to be batch processed. In this way, fifo_batch is not the upper limit of the batch mechanism, but it only provides opportunities for timeout and hunger requests. If there is no timeout and no hunger, of course, continuing batch processing of requests in order will increase efficiency. Thermal Cutout,Capillary Type Thermostat,Freezer Used Thermostat,Adjustable Thermostat Foshan City Jiulong Machine Co., Ltd , https://www.jlthermostat.com